Replicated load-balanced service in Kubernetes
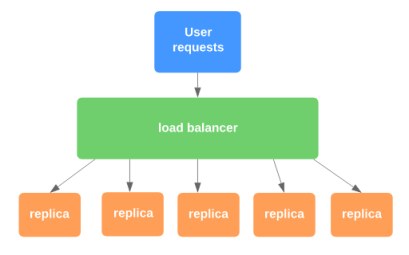
A stateless service is a basic component of a modern, distributed system. It is widely used due to its ease of implementation and ability to handle a high volume of traffic by adding more instances. A typical Kubernetes implementation includes a load balancer and one or more replicas. The load balancer is placed at the entry point of the system to route incoming requests to the replicas. The routing methods can vary, ranging from a simple round-robin approach to more advanced techniques such as session stickiness or load balancing based on system performance.
Replication is an important aspect of a stateless service, as it ensures that the system remains operational even if one replica fails. At least two replicas are required to provide continued availability in the event of a failure. When one replica crashes, the load balancer redirects all requests to the remaining healthy instances. Additionally, replication enables software upgrades by allowing one replica to be taken offline for upgrading while the other replicas continue to serve requests.
Health checks
A replica set in Kubernetes ensures that the cluster remains in a stable state by monitoring its health. To identify unhealthy pods, different types of health checks, called probes, are used. One of the most common is the liveness probe, which is often configured as an endpoint that is periodically checked and must return a success code to confirm that the pod is healthy. This can be an HTTP endpoint that returns a code indicating a healthy state. If the probe times out or returns a failure code, the pod is considered unhealthy and is recreated. Health probes are not limited to HTTP requests and can also be shell commands that return a result. If the result equals 0, the pod is considered healthy.
In some cases, an application may be temporarily unavailable, for example, during startup initialization. To give the application time to complete initialization without interruption, a readiness probe can be used. The readiness probe tells Kubernetes to not perform the liveness probe for a specified amount of time.
Test application
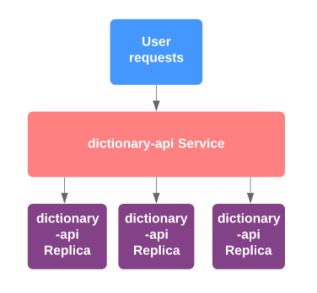
To illustrate the approach, I created a simple web service. It takes an English word as input and looks up its definition in a dictionary. The dictionary is a JSON file containing over 466,000 English words. The service accepts an input word in the following format: http://localhost:30212/api/dictionary?word=yellow.
My plan is to create three service replicas to evenly distribute traffic.
Docker
The test application is built using ASP Web API Core and has the following dockerfile.
FROM mcr.microsoft.com/dotnet/core/sdk:2.2 WORKDIR /dictionary COPY . . RUN dotnet restore RUN dotnet publish -o /publish ENTRYPOINT ["dotnet", "/publish/DictionaryApi.dll"]This command will build a docker image named dictionary:api.
Kubernetes
dictionary.deployment.yaml defines a deployment that uses a docker image dictionary:api to create three pods to expose the service on port 80.
apiVersion: apps/v1 kind: Deployment metadata: name: dictionary-api spec: selector: matchLabels: name: dictionary-api replicas: 3 template: metadata: labels: name: dictionary-api spec: containers: - name: dictionary-api image: dictionary:api ports: - containerPort: 80The following command instructs Kubernetes to create all necessary resources.
service.deployment.yaml contains the definition of the service.
kind: Service apiVersion: v1 metadata: name: dictionary-api-service spec: selector: name: dictionary-api ports: - protocol: TCP port: 80 targetPort: 80 name: dictionary-api type: NodePort


Challenges of a serverless architecture
Serverless computing is so popular today that many developers consider it as the first choice for any cloud-based implementation. Despite many obvious benefits, this type of architecture has some drawbacks that are not visible at first sight. In this post I am going to describe common challenges that a developer can face by choosing a serverless architecture.
Definitions of a serverless architecture may vary but the key components remain the same: “Backend as a Service” (or BaaS ) and “Functions as a Service” (or FaaS). Strictly speaking, serverless computing does not necessarily involve Baas or FaaS. I can think of a system that does not take advantage of FaaS but is truly serverless. In this post I am focused on the FaaS component of a serverless architecture.
Startup latency
Since a function is stateless, it takes some time for a platform to initialize an instance of the function. The procedure, known as cold start, includes the following steps.
- Retrieve the function from the storage
- Schedule the function on some computing host
- Load and initialize an underlying infrastructure (.Net, Java, Node, etc)
- Run the function and perform some custom initialization logic, e.g. load some state from an external storage
Depending on different factors cold start can take hundreds of milliseconds or several seconds. This might be unacceptable in some scenarios, although a platform often caches an instance of a function for some period of time. This technique is called hot start. After a certain time of inactivity, the platform releases the resources so the next invocation requires cold start.
Execution duration and other limits
All major cloud providers that support FaaS (Azure, AWS, Google) have restrictions regarding the utilization of shared cloud resources. For instance, an Azure function is aborted if it runs longer than five (or ten) minutes, making harder to use the function for a long-lived workflow. Also, there are some limits related to the number of concurrent calls or memory usage. This has been consistent now for a few years, but Azure has shown some signs of changes.
I/O performance
Functions that share computation resources also share the same network, so throughput might be limited, which is not convenient for big data solutions, for instance.
State
A function is stateless by definition so if it needs a state it must load it from some external resource on startup and flush at the end of the invocation. This requirement can drastically affect the performance since any sort of off instance storage is not nearly as fast as in memory storage.
Caching
Due to the stateless nature of a function caching of HTTP response can’t be implemented as efficiently as it is done by using a traditional Web server that has local storage. A cache must be externalized in order to be used in a function.
Relational database servers often are not optimized for FaaS platforms
Take an instance of working on a system where Azure Function is called to handle an incoming message that appears in Azure Service Bus subscription. The handler reads the database (Azure SQL server) and then updates several tables depending on internal logic. It works perfectly until the load reaches some level where SQL Server refuses to create a new connection. It turns out that many relational stores are not well optimized to handle a lot of concurrent connections. Instead, they expect the client to establish one connection and keep using it as long as possible.
For some reason, Azure Function does not support a batching mechanism in Azure Service Bus binding, e.g. there is no way to retrieve a batch of messages and process them in one transaction. The solution is to create a function that periodically runs and process all messages at once.
Why a continuation token should be the first thing to consider when it comes to paging
I think there is no need to sell the idea of pagination when we talk about collections in Web API. A pagination allows a developer to split potentially unlimited amount of data into reasonably sized portions that don’t add extra load on a server and is easily consumed by a client.
Client-driven paging assumes that the client considers the collection of resources as a collection of pages of the same size ordered by some criteria. An arbitrary page can be accessed by specifying a page number and a page size.
http://myservice/customers?page=2&page_size=100
From the implementation perspective it is clearer to see it as a sequence of steps.
- Order the collection by some criteria
- Skip the first 200 elements
- Return the remaining 100 elements
This method is also known as LIMIT/OFFSET (or as MS likes to call it, TOP/SEEK) approach because of the way it is often implemented in relational databases.
But despite its prevalence, it has a serious drawback because it results in O(n²) operations. In a nutshell, this technique requires an entire collection to be fetched and ordered before returning a piece of data. It might not be a problem for a small database but once the database has grown in size it can seriously affect the application’s performance. You can find more on this in the article: https://use-the-index-luke.com/no-offset
Server-driven paging does not give the client control over the size of a page or ability to access an arbitrary page. Instead, the server returns a page of a predefined size and a link to the next page called a continuation token. A continuation token is often a value of an index field that is used to sort data. In the example above, it might be an auto incremented value that uniquely identifies a customer and is used to order customers in the database. Usually a continuation token is returned in the header of a response and then passed in the header of a subsequent request.
x-continuation-token: 2034
This approach assumes that the pages are processed sequentially, i.e. page 0, page 1, page 2 etc. Of course, it is not applicable if you want to access a random page.
Don’t use exceptions for validation
Exceptions are often used for validation. In the code below we check if a name of a customer is already exist in a repository and throw an exception if it is true. The exception is used to pass validation error message.
public Customer AddCustomer(string firstName, string lastName)
{
if(customers.Any(x => x.FirstName == firstName && x.LastName == lastName))
throw new Exception($"Failed to add a customer: the customer with this name already exists");
var customer = new Customer(firstName, lastName);
customers.Add(customer);
return customer;
}
The client code is below.
try
{
Customer customer = repository.AddCustomer("Vlad", "Sukhachev");
repository.Save();
}
catch (Exception e)
{
ShowValidationError(e.Message);
}
There are two problems with this approach. First, the signature of AddCustomer is dishonest. In order to realize that this method throws an exception the developer has to review the source code. The second concern is more subtle. By the definition, the exception is used to signal an exceptional situation which is a result of a bug in code. Wrong user input certainly does not fit into this category.
In order to fix this issue we need to use Result class from CSharpFunctionalExtensions. Now the repository code looks like this.
public Result<Customer> AddCustomer(string firstName, string lastName)
{
if (customers.Any(x => x.FirstName == firstName && x.LastName == lastName))
return Result.Fail<Customer>($"Failed to add a customer: the customer with this name already exists");
var customer = new Customer(firstName, lastName);
customers.Add(customer);
return Result.Ok(customer);
}
And the client code.
Result<Customer> result = repository.AddCustomer("Vlad", "Sukhachev");
if(result.IsFailure)
ShowValidationError(result.Error);
repository.Save();
Now when we look at the signature of AddCustomer method we can say that it can return a result indicating failure and we don’t use an exception to pass validation error. That does not mean that we should avoid using exceptions. Even in this simplified example there is a legal case where an exception is relevant. CustomerRepository.Save can raise an exception in case of any database related issue.
Introduction to TPL Dataflow
TPL Dataflow Library is one of underestimated libraries which have not gained as much popularity as other TPL components. I believe the main reason is a fact that Microsoft did not include Dataflow Library in the .NET Framework 4.5, you should install it separately. Anyway in this post I am going to quickly describe main features of TPL Dataflow and answer a question why and when you need to use this library.
TPL Dataflow Library is designed to help programmers write concurrent enabled applications. You may say that this is what TPL is all about. True, but Dataflow Library is supposed to be used in very specific scenarios. Imagine you are developing an application that has to process many request which is typical scenario for server side applications. And processing of a request involves many concurrent tasks: Web API calls, database transactions, file IO operations, image processing etc. Also you want to be able to control resource utilization in order to keep your server responsive. Certainly, you can do everything described above using TPL tasks, develop own queues for message prioritization and use synchronization primitives to protect shared data. TPL Dataflow provides a programming model that hides low level details of managing concurrent workflows and allows you to focus on your business logic.
Programming Model
The main concept in Dataflow is a block. You can consider a block as data structure that can buffer and process data. Normally your Dataflow application is a collection of linked blocks forming a workflow specific for your needs. Actual communication between blocks is organized in a form of messages passed from one block (source) to another (target). There are different types of blocks: data transform block, buffer block, action block. You can build a simple pipeline which is a linear sequence of blocks or network, which is a graph of blocks.
Common blocks
Transform block
Transform block is used to receive input value and return transformed value. In the example below TransformBlock receives user names and returns user photos.
var photoService = new PhotoService();
var transformBlock = new TransformBlock<string, Photo>(async userName =>
{
Photo userPhoto = await photoService.GetUserPhoto(userName);
return userPhoto;
});
Web API versioning in real world applications
Once you have published your API it is set in stone. Customers who use your API expect it to not change. Otherwise their code may fail due to changed contract or behavior. But requirements will change and we need to figure out a way to evolve API without breaking existing clients. So every time when a breaking API change occurs you need to release a new version of API. That does not mean you need to support all versions forever. But you need to get rid of old versions of API with some care so customers have an idea how to move to a newer version of API.
In this post I am going to discuss how Web API versioning affects entire application and provide some recommendations how to organize source code to maintain different versions of API.
Example project can be downloaded here.
Introducing test application
In order to illustrate API versioning strategies we are going to develop a simple Web API for retrieving tasks. A task contains Name, Description, Owner and task state attributes: IsStarted and IsFinished. Each task belongs to particular Project which is barely a container of tasks. Application consists of three layers:
- Domain layer that includes Task and Project definition
- Data access layer that defines TaskRepository class. TaskRepository uses domain classes in serialization.
- Distributes services layer defines DTO’s used by TaskController

OAuth 2 flows: Client flow
Client flow is used solely for machine to machine communication, i.e. no Resource Owner involved. Client sends client_id and secret to Authorization Server and then receives access_token and refresh_token.
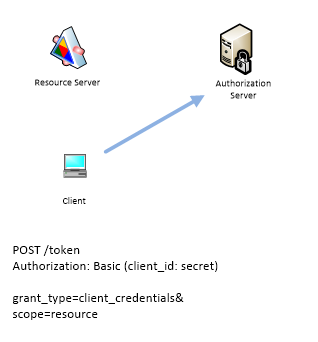
This type of flow is usually used when Web application needs to access Web API.
OAuth 2 flows: Resource Owner Credentials flow
This type of flow is used when Resource Owner trusts the Client. Client might be mobile application, desktop application or browser application communicating with Web server. Device where Client is installed is trusted as well so user name and password can be stored on this device. In this flow Resource Owner enters user name and password in the UI provided by Client. Then Client sends POST request to Authorization server. The request contains entered user name and password.

Authorization Server responds with access_token and refresh_token.

access_token is included in each request that Client sends to Resource Server.
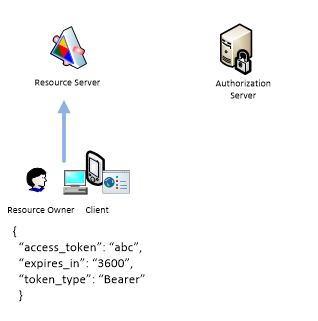
When access_token is expired Client can repeat this procedure, i.e. send user name and password and collect new access token or it can use refresh_token. Ideally Client should not store user credentials. Instead it should ask for user credentials once, collect refresh_token and then use it forever to obtain new refresh_token. access_token and refresh_token might be stored on a device.
OAuth 2 flows: Implicit flow
Implicit flow is probably the most common scenario. It is used when Client is mobile application (IOS, Android, Windows Phone) or native application or browser mobile application which wants to access resource on the behalf of Resource Owner.
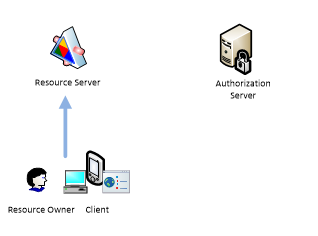
Resource Server redirects application to Authorization Server. client_id identifies application, redirect_uri specifies Uri where Client will be redirected after authorization completed.
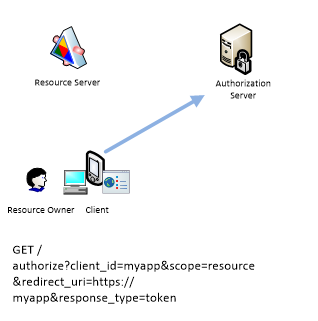
Then Authorization Server asks user to authorize. Depending on particular implementation (Google, Twitter, Facebook) the login screen might look different.
The next step is Consent screen where Resource Owner will be prompted to allow application to perform certain actions.
When authorization is complete the Authorization Server executes redirect_uri passing access token and expiration interval.
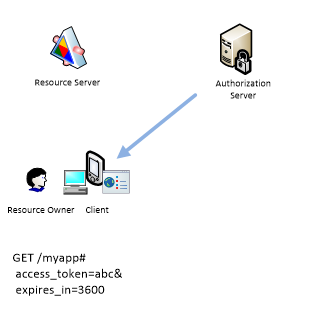
Notice that access_token and expires_in are specified after pound character which assumes that they never passed to the Resource Server. So Client can extract access_token and include it in the next requests.
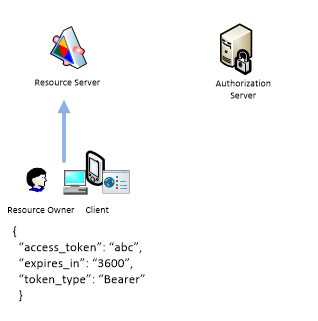
This flow does not use refresh token since this implies that user name and password must be stored on a device which can not be considered as secured. So user should periodically repeat the authorization procedure.
OAuth2 flows: Authorization flow
Authorization flow is usually used when Resourse Owner communicates with Web server which accesses another RESTful web service on behalf of the Resource Owner.

Client redirects Resource Owner to Authorization Server. In the url Client specifies client_id which is how Authorization Server identifies the Client. Assumed that Client was previously registered on the Authorization server. Also Client specifies redirect_uri which Authorization Server will use when Resource Owner authorization is complete.

Then Authorization Server asks user to authorize. Depending on particular implementation (Google, Twitter, Facebook) the login screen might look different.

The next step is Consent screen where Resource Owner will be prompted to allow application to perform certain actions.

When authorization is complete the Authorization Server redirects Resource Owner back to the Client.

It passes code parameter but this is not a token yet. This code will be used by Client which will send a request to Authorization Server.

Authorization Server responds with access token, refresh token and expiration time in seconds.
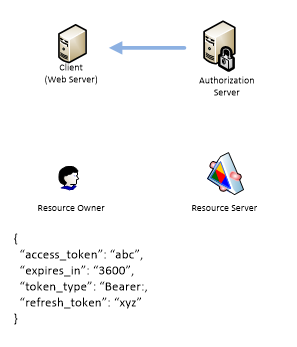
So now Client can access Resource Server by using access token.

As you can see access token time life is very short. So when it is expired there are two options. Client can start this procedure over or use refresh token to request new access token.
So Authorization flow has the following features.
- Used for server side applications
- Resource owner never gets access token so it can not leak
- If access token is expired it can be requested again using refresh token
